work / ai / research / brain-tumor-segmentation
Brain Tumor Segmentation & Classification
A deep-learning pipeline that segments and classifies brain tumors from MRI, comparing U-Net variants and three CNN classifiers on the BRISC 2025 dataset.
- test dice
- 88.22%
- U-Net on 860 unseen samples
- classification
- 97.50%
- DenseNet-121 accuracy
- pixel accuracy
- 99.61%
- U-Net segmentation
- models trained
- 27
- 7 main + 20 hyperparameter runs
system architecture / interactive
The clinical problem
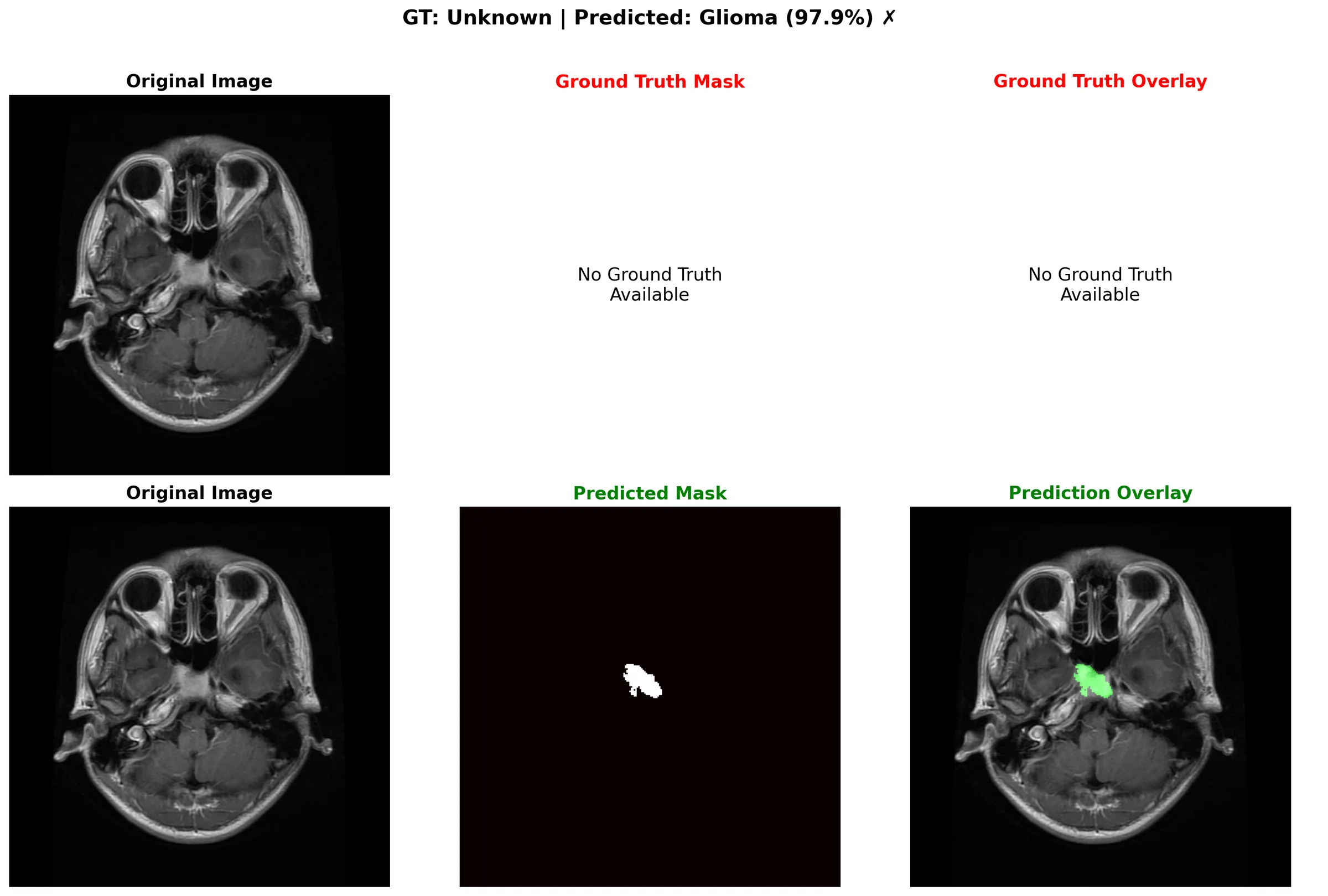
Brain-tumor diagnosis and treatment planning depend on accurate segmentation and classification of MRI scans, but manual annotation is slow and suffers from inter-observer variability. This project builds and rigorously evaluates automated deep-learning solutions on the BRISC 2025 dataset, which covers four categories: glioma, meningioma, pituitary, and no-tumor. The dataset provides 5,000 training images with segmentation masks and 1,000 test images at 256x256 grayscale, with 3,933 valid image-mask pairs for the segmentation task.
Two tasks, two architectures
I treated segmentation and classification as distinct problems and built dedicated models for each.
For segmentation, a vanilla U-Net (five-level encoder-decoder, skip connections, base filters of 64 doubling per level, sigmoid output) served as the baseline. I then built an Attention U-Net that adds attention gates to focus on relevant spatial regions and suppress irrelevant features. Both trained on a combined Dice-BCE loss:
For classification, I compared three ImageNet-scale CNNs of increasing capacity: MobileNetV2 (~3.5M params), EfficientNet-B0 (~5.3M), and DenseNet-121 (~8M).
Everything trained with Adam, a learning rate of 1e-4, batch size 16, and up to 100 epochs with early stopping (patience 15), augmented with flips, rotations up to 15 degrees, affine transforms, brightness/contrast jitter, and Gaussian noise, all on a single 8GB RTX 3070.
The results that mattered
On the 860-sample unseen test set, U-Net won every segmentation metric: 88.22% Dice, 79.74% mIoU, and 99.61% pixel accuracy, edging out Attention U-Net across the board. Notably, test performance exceeded validation by roughly five points, which indicated robust training rather than overfitting.
For classification, DenseNet-121 led at 97.50% accuracy (97.48% F1), with per-class F1 scores between 96.9% and 98.0%. EfficientNet-B0 offered the best efficiency-performance trade-off at 97.30% for a smaller footprint.
| Task | Best model | Headline metric |
|---|---|---|
| Segmentation | U-Net | 88.22% Dice, 79.74% mIoU |
| Classification | DenseNet-121 | 97.50% accuracy |
| Efficiency pick | EfficientNet-B0 | 97.30% accuracy, 54 MB |
The finding I did not expect
I ran a joint multi-task model that shared an encoder between segmentation and classification, expecting the usual "shared representations help both tasks" story. It did not hold. Joint training underperformed separate training by 4.91 points on Dice and 5.81 points on classification accuracy. The shared encoder created task interference, loss balancing was hard to tune, and the dataset simply was not large enough to support effective multi-task learning. The honest recommendation for this dataset is to train task-specific models.
Attention U-Net told a similar story: the attention mechanism did not improve results, likely because the dataset is modest and the tumor boundaries are simple enough that U-Net's skip connections already capture the relevant features.
Hyperparameter study
A systematic 20-run grid over four optimizers (Adam, SGD, AdamW, RMSprop) and five learning rates confirmed that Adam at 5e-5 was optimal (78.57% Dice in the shortened 20-epoch budget). SGD needed higher learning rates and struggled with very small ones. In total the project trained 27 models across roughly 52 hours of GPU time and about 4,000 lines of code.
Explore it
The interactive playground lets you page through real inference panels from the test set, compare U-Net against Attention U-Net, and inspect the confusion matrix and per-class metrics directly.
stack
the evidence